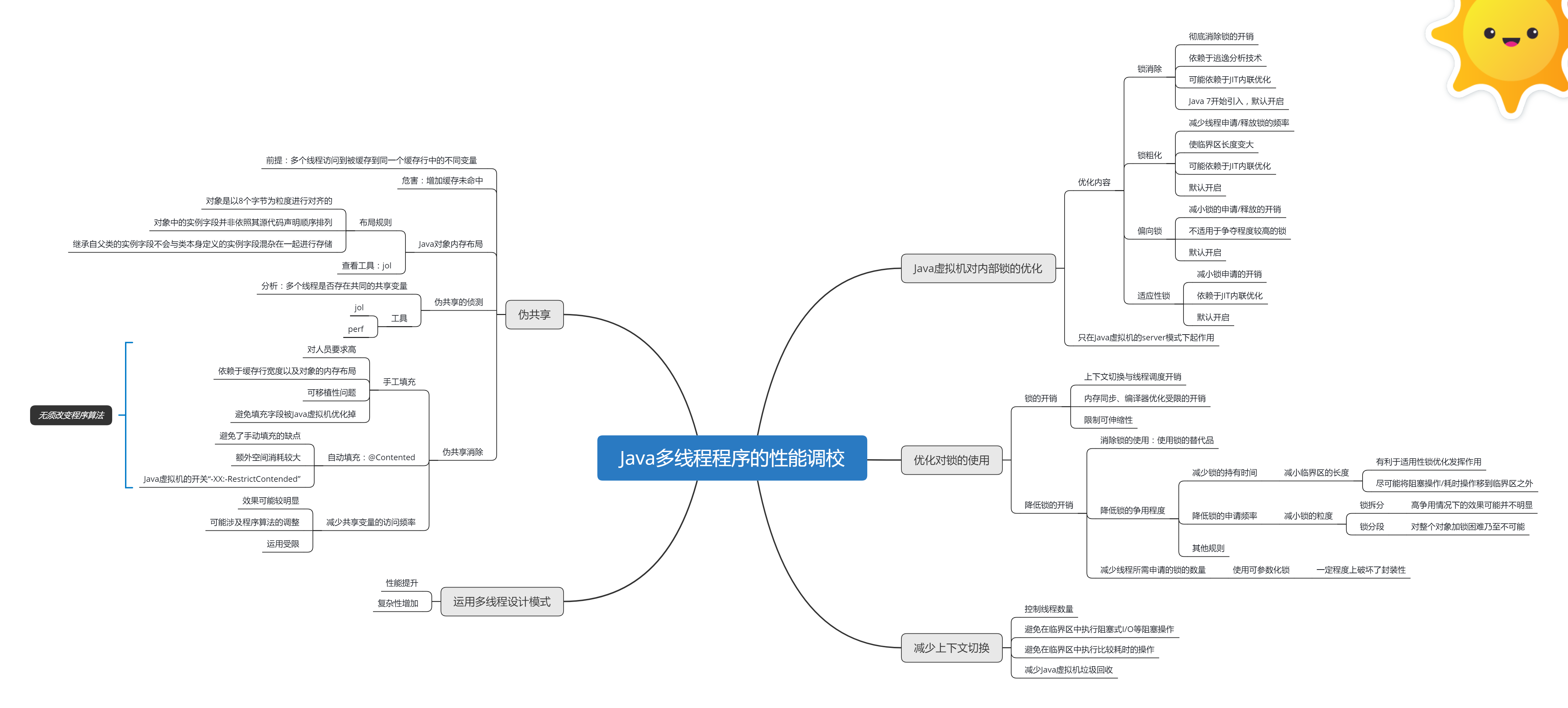
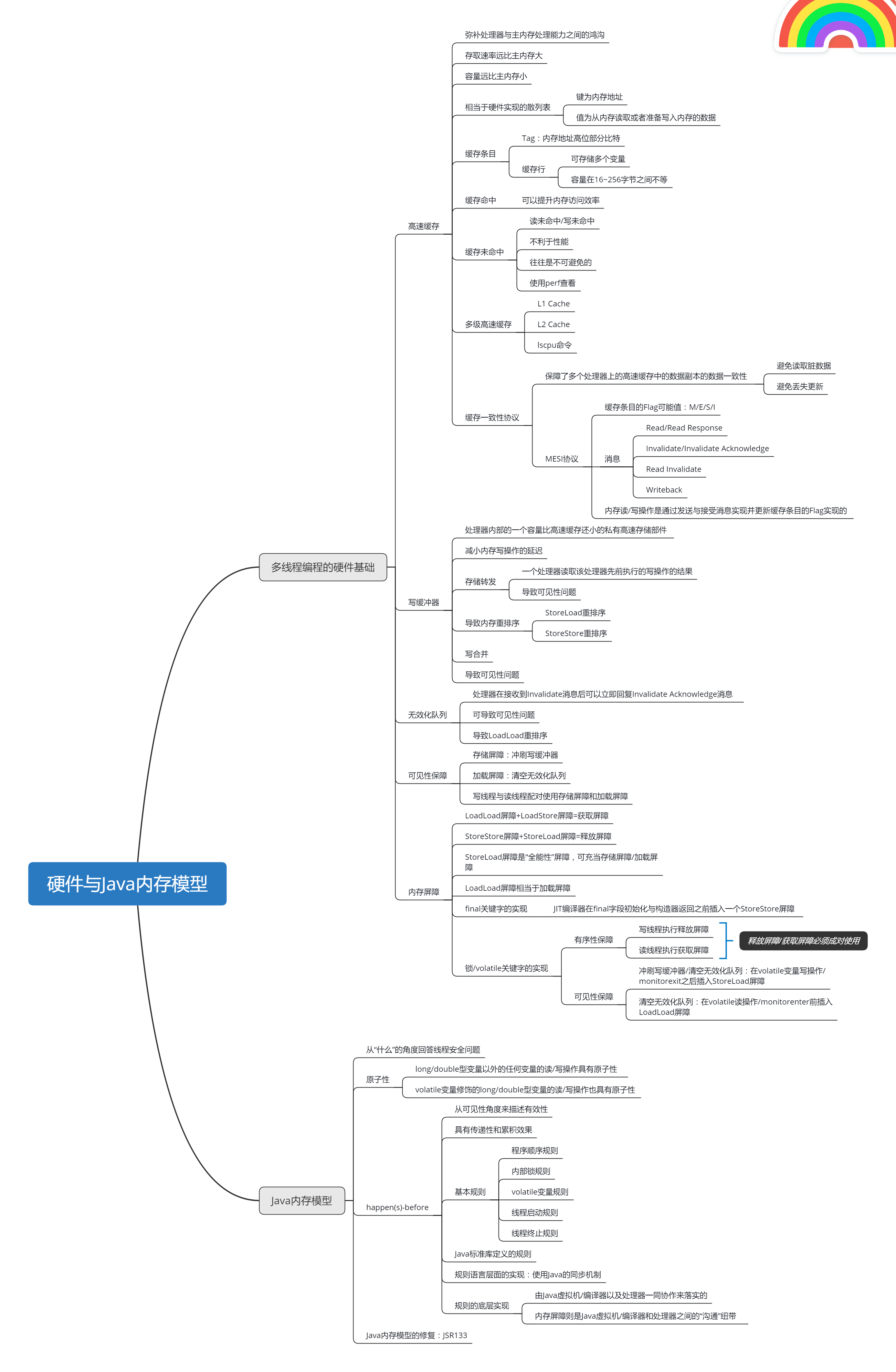
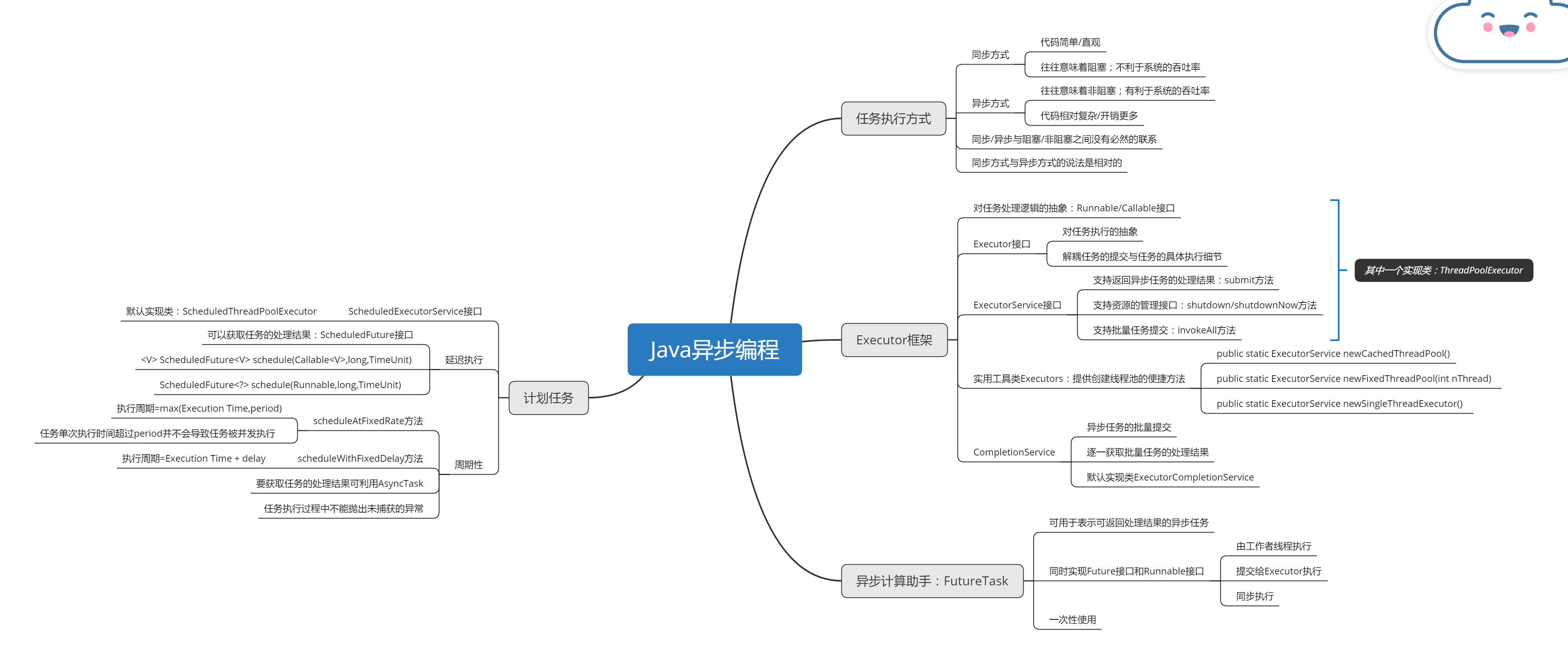
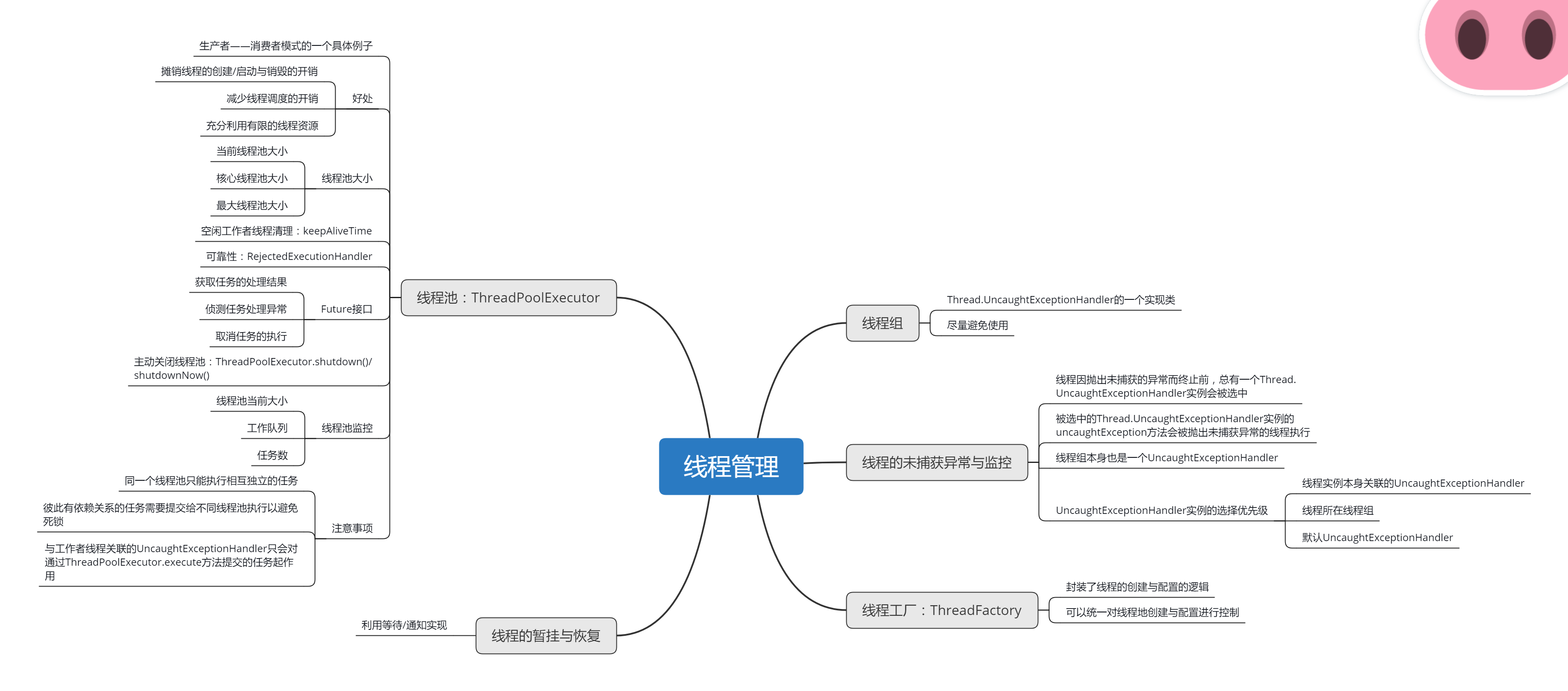
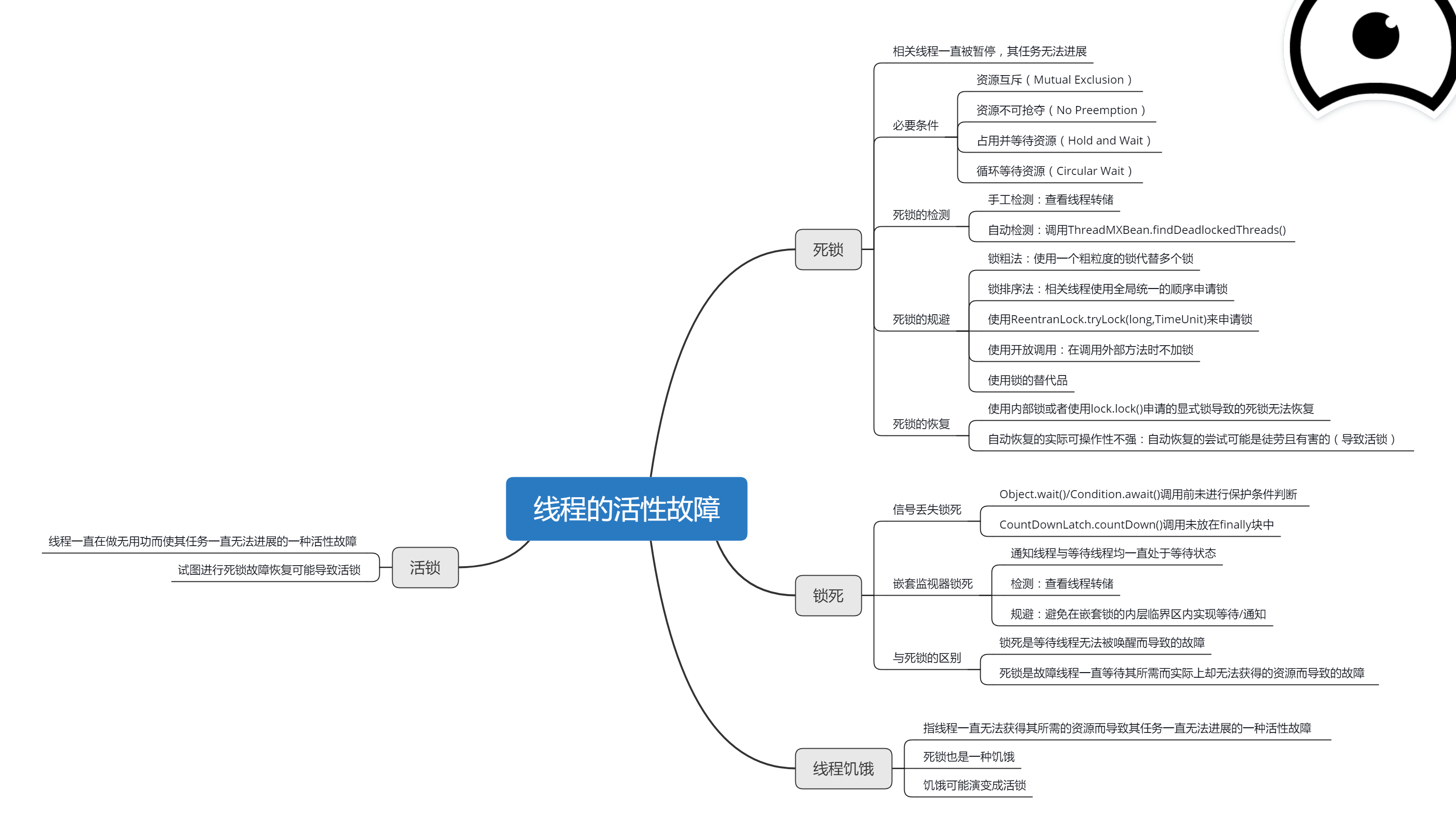
逛 Spring 官网学习总结
@RepositoryRestResource 看到这个注解,之前一直没有用到过,所以想要自己试试效果,顺道做下总结。
不想要看我废话想要直接看官网的 → Accessing JPA Data with REST
不想要看我废话想看大佬的 → Spring Boot之@RepositoryRestResource注解入门使用教程
构建项目 用 Maven 构建项目,建一个 Person 实体类,再建一个 PersonRepository 接口,这个是关键。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package hello; import java.util.List; import org.springframework.data.repository.PagingAndSortingRepository; import org.springframework.data.repository.query.Param; import org.springframework.data.rest.core.annotation.RepositoryRestResource; @RepositoryRestResource(collectionResourceRel = "people", path = "people") public interface PersonRepository extends PagingAndSortingRepository<Person, Long> { List<Person> findByLastName(@Param("name") String name); }
官网是这么介绍的:
1 At runtime, Spring Data REST will create an implementation of this interface automatically. Then it will use the @RepositoryRestResource annotation to direct Spring MVC to create RESTful endpoints at /people.
我们翻译过来就是:
1 在运行时,Spring Data REST将自动创建此接口的实现。然后它将会在使用 @RepositoryRestResource 注解的 Spring MVC 在 /people 创建 RESTful 端点。
点进 PagingAndSortingRepository 接口看:
1 2 3 4 5 6 @NoRepositoryBean public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> { Iterable<T> findAll(Sort var1); Page<T> findAll(Pageable var1); }
看到该接口还是继承了平时常使用的 CrudRepository,这就说明那些基本的增删改查方法也都有。
为了方便,我还写了一个接口用来保存 Person 实体,为后续测试使用。
1 2 3 4 5 6 7 8 9 10 @Service public class PersonService { @Autowired PersonRepository personRepository; public void savePerson(Person person){ personRepository.save(person); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 @RestController @RequestMapping("/person") public class PersonController { @Autowired PersonService personService; @PutMapping("/save") public String savePerson(Person person){ personService.savePerson(person); return "success"; } }
很简单的一个映射。
到这为止,我们的项目就全构建好了。
嫌麻烦不想自己动手建项目的 → GitHub
测试功能 我这里为了方便,用的是 Postman 进行测试。
首先访问 http://localhost:8080,返回的是:
1 2 3 4 5 6 7 8 9 10 11 { "_links": { "people": { "href": "http://localhost:8080/people{?page,size,sort}", "templated": true }, "profile": { "href": "http://localhost:8080/profile" } } }
再访问 http://localhost:8080/people,返回的是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 { "_embedded": { "people": [] }, "_links": { "self": { "href": "http://localhost:8080/people{?page,size,sort}", "templated": true }, "profile": { "href": "http://localhost:8080/profile/people" }, "search": { "href": "http://localhost:8080/people/search" } }, "page": { "size": 20, "totalElements": 0, "totalPages": 0, "number": 0 } }
因为里面没有数据,我们先塞几个数据进去,这时候就利用我们之前写的接口来操作。如下:
1 2 3 我们用 PUT 方式去请求 http://localhost:8080/person/save?firstName=aaa&lastName=bbb 返回 success 就说明操作成功,成功塞入。
同样的方式我们再多塞几个。
塞完值之后我们接着去访问 http://localhost:8080/people,这时候发现结果与之前的稍有不同了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 { "_embedded": { "people": [ { "firstName": "aaa", "lastName": "bbb", "_links": { "self": { "href": "http://localhost:8080/people/1" }, "person": { "href": "http://localhost:8080/people/1" } } }, { "firstName": "aaa", "lastName": "ccc", "_links": { "self": { "href": "http://localhost:8080/people/2" }, "person": { "href": "http://localhost:8080/people/2" } } }, { "firstName": "jay", "lastName": "folger", "_links": { "self": { "href": "http://localhost:8080/people/3" }, "person": { "href": "http://localhost:8080/people/3" } } } ] }, "_links": { "self": { "href": "http://localhost:8080/people{?page,size,sort}", "templated": true }, "profile": { "href": "http://localhost:8080/profile/people" }, "search": { "href": "http://localhost:8080/people/search" } }, "page": { "size": 20, "totalElements": 3, "totalPages": 1, "number": 0 } }
是的,我们刚塞的值都查出来了。
接着测试,访问 http://localhost:8080/people/1,返回结果为:
1 2 3 4 5 6 7 8 9 10 11 12 { "firstName": "aaa", "lastName": "bbb", "_links": { "self": { "href": "http://localhost:8080/people/1" }, "person": { "href": "http://localhost:8080/people/1" } } }
是的,就是第一条数据被查出来了,同理 /2 /3 也是。
访问 http://localhost:8080/people/search,返回结果为:
1 2 3 4 5 6 7 8 9 10 11 { "_links": { "findByLastName": { "href": "http://localhost:8080/people/search/findByLastName{?name}", "templated": true }, "self": { "href": "http://localhost:8080/people/search" } } }
对的,findByLastName{?name} 就是我们在里面新增的那个接口,那就顺着这个意思咱们继续来。
访问 http://localhost:8080/people/search/findByLastName?name=folger,返回结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 { "_embedded": { "people": [ { "firstName": "jay", "lastName": "folger", "_links": { "self": { "href": "http://localhost:8080/people/3" }, "person": { "href": "http://localhost:8080/people/3" } } } ] }, "_links": { "self": { "href": "http://localhost:8080/people/search/findByLastName?name=folger" } } }
与我们猜测无二。接口写的返回是集合,所以就返回了一个集合。
之前还看到了这么一条 link "href": "http://localhost:8080/people{?page,size,sort}"
有经验的程序员一眼就肯定知道这些个参数都是干什么用的,是啊,就是分页用的。
我们访问这个 url : http://localhost:8080/people?page=0&size=4&sort=lastName,返回的结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 { "_embedded": { "people": [ { "firstName": "aaa", "lastName": "bbb", "_links": { "self": { "href": "http://localhost:8080/people/1" }, "person": { "href": "http://localhost:8080/people/1" } } }, { "firstName": "aaa", "lastName": "ccc", "_links": { "self": { "href": "http://localhost:8080/people/2" }, "person": { "href": "http://localhost:8080/people/2" } } }, { "firstName": "ccc", "lastName": "ccc", "_links": { "self": { "href": "http://localhost:8080/people/4" }, "person": { "href": "http://localhost:8080/people/4" } } }, { "firstName": "jay", "lastName": "folger", "_links": { "self": { "href": "http://localhost:8080/people/3" }, "person": { "href": "http://localhost:8080/people/3" } } } ] }, "_links": { "self": { "href": "http://localhost:8080/people" }, "profile": { "href": "http://localhost:8080/profile/people" }, "search": { "href": "http://localhost:8080/people/search" } }, "page": { "size": 4, "totalElements": 4, "totalPages": 1, "number": 0 } }
从返回的数据我们可以看出: page 当然是页数,size 就是每一页的个数,sort 就是排序的字段,默认为 asc。
这一波测试下来发现这样封装之后之前需要一大堆代码才能实现的分页,这里只需要一个注解即可。妙啊妙不可言。
相关链接